

11月16日上午,“统计大讲堂”系列讲座第一百三十六讲举行。本次讲座采取在线直播的方式,清华大学统计学研究中心博士林毓聪受邀作题为“High-throughput medical knowledge mining from large-scale texts and electronic healthcare records”的报告。统计学院教师、应用统计科学研究中心研究员李扬、尹建鑫、吕晓玲、孙怡帆等老师参加。讲座由统计学院教师李伟主持。
李伟首先介绍了报告人的相关信息。林毓聪是清华大学统计学研究中心博士,哈佛大学医学院蔡天西教授组访问学者。他的主要研究方向为医学信息学、医学知识挖掘与图谱构建、自然语言模型构建以及神经网络建模等。他的主要工作发表在医学信息学一区期刊Journal of Biomedical Informatics, BMC Medical Informatics and Decision Making与核心会议IEEE International Conference on Healthcare Informatics中。

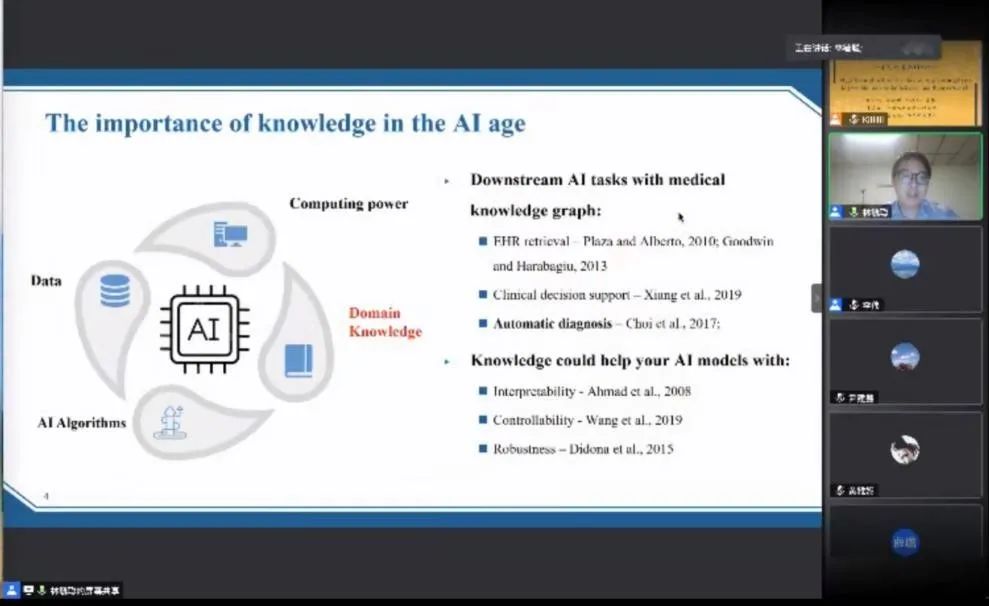
林毓聪首先介绍了医学知识挖掘的重要性。在人工智能时代,数据、算法、算例是最常见的三要素;但随着时代的发展,通过堆砌数据和算例获得的模型准确率已经到达瓶颈,而领域背景知识的重要性不断提升。他指出,医学知识挖掘在医学领域的应用越来越广泛。通过列举医学知识图谱在电子病例检索中的应用、自动诊断模型在辅助乡镇医院诊疗中的应用等将数据与医学知识紧密结合的例子,他详细分析了医学知识的重要性并强调了好的背景知识能够使模型更具备理解性、可控性和可泛化能力。
林毓聪回顾了关于关系提取模型的系列工作。从传统的机器学习方法到现如今的深度学习方法,科研人员在公开数据集上不断尝试开发新的关系提取模型,意在从句子中提取更多能够表达关系对的特征。然而许多关于文本数据处理的文章都使用公开数据集来构建模型,而这些数据集与真实的医学数据有一定差异,这导致无法直接将已有的数据集与方法用于实际的医学关系提取中。因此林毓聪及其团队提出了构建Hi-RES框架的设想。他指出,为将更多医学知识融入模型中,需要从零开始,通过数据挖掘、获取数据、构建训练集和测试集,提出一个适用的模型。
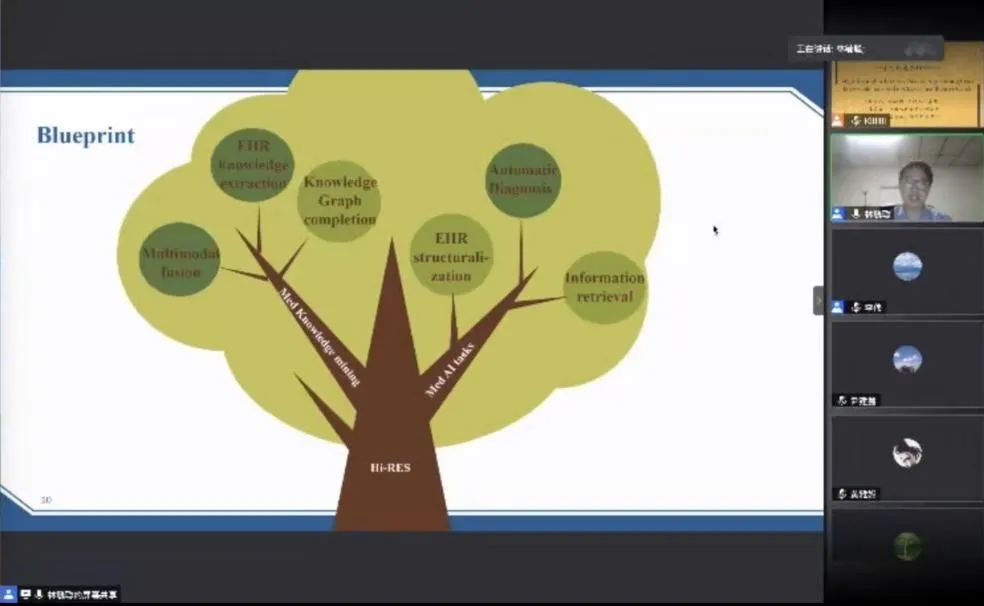
在构建Hi-RES框架的基础上,林毓聪及其团队做了两个层面的深度研究:一是在知识挖掘层面继续深挖,融合更多数据源、图像、已有的知识图谱和电子病历等,或者直接从电子病历中进行关系挖掘;二是尝试更多下游任务,例如医学电子病历的结构化、电子病历的检索、自动诊断模型等。关于Hi-RES框架,林毓聪通过列举糖尿病与体重变化的关系等例子,阐释了框架提出的细节、难点以及应用。
在交流讨论环节,在线师生积极提问,林毓聪一一详细解答,并对Hi-RES框架在中文电子病历方面的应用作了进一步阐释。
本次讲座内容充实,条理清晰,理论与实例相结合,真实展现了医学知识挖掘的重要性和实用性。此后“统计大讲堂”系列将继续推出更多精彩讲座,敬请关注。