

12月9日下午,统计大讲堂”系列讲座第138讲举行。本次讲座采取在线会议的方式,邀请山东大学金融研究院研究员何勇作题为“Simultaneous Differential Network Analysis and Classification for Matrix-variate Data with Application to Brain Connectivity”的报告,统计学院教师王武参加。讲座由统计学院副院长、应用统计科学研究中心研究员李扬主持。
李扬首先介绍了报告人的相关信息。何勇是山东大学金融研究院研究员,山东大学学士,复旦大学博士。他从事金融计量统计、生物统计以及机器学习等方面的研究,在国际统计学权威期刊Biometrics, Journal of Business and Economic Statistics, Bioinformatics, Statistics in Medicine, Journal of Multivariate Analysis和中国科学:数学等发表研究论文20余篇。
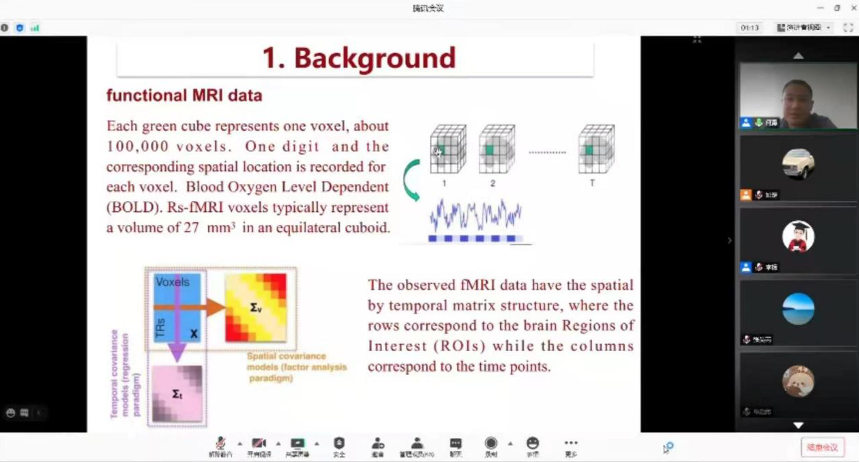
何勇首先介绍研究的背景,研究目的是探究阿尔茨海默病患者哪些脑区间关系的变化引起的该疾病,并由此作为特征进行诊断预测,基于rs-fMRI图像成像原理,将每个个体大脑的rs-fMRI数据经过预处理得到相应的矩阵数据,矩阵中每一行代表不同脑区,每一列代表各个时刻,以此研究各个脑区之间的联系,从而为阿尔茨海默病的发病机理与诊断预测提供分析工具。大量实验证明,大脑中不同脑区之间存在一定的功能性连接。该研究对于诊断阿尔茨海默病问题,采用带惩罚项的逻辑回归方法。
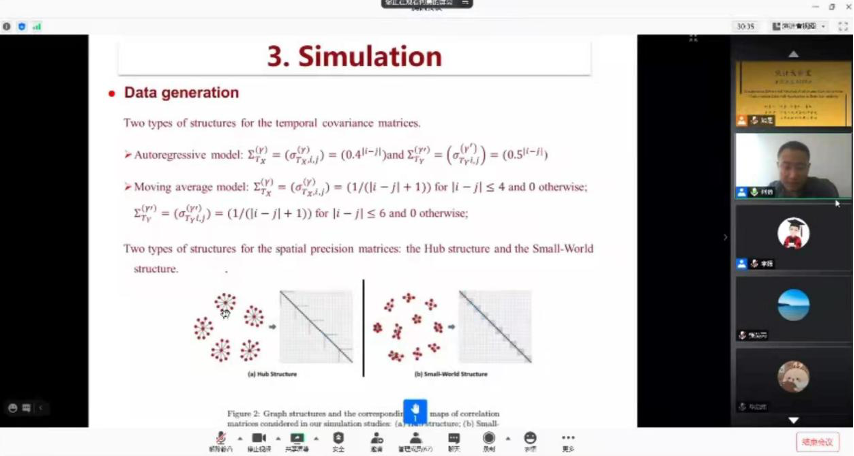
在介绍研究方法时,何勇指出了研究面临的挑战,包括如何处理高维的矩阵数据并建模、如何在差异网络分析中去除混杂因素的影响等。针对以上问题,研究提出了一种比现有机器学习方法都更优化、网络比较表现更好的集成方法(SDNCMV)。何勇将此方法具体分为三个步骤,即对数据预处理并估计个体网络、结合惩罚方法和Logistic模型进行分析以及通过重抽样的方法使最终得到的结果更稳健,他还将研究的模拟结果与其他现有方法的模拟结果进行比较。
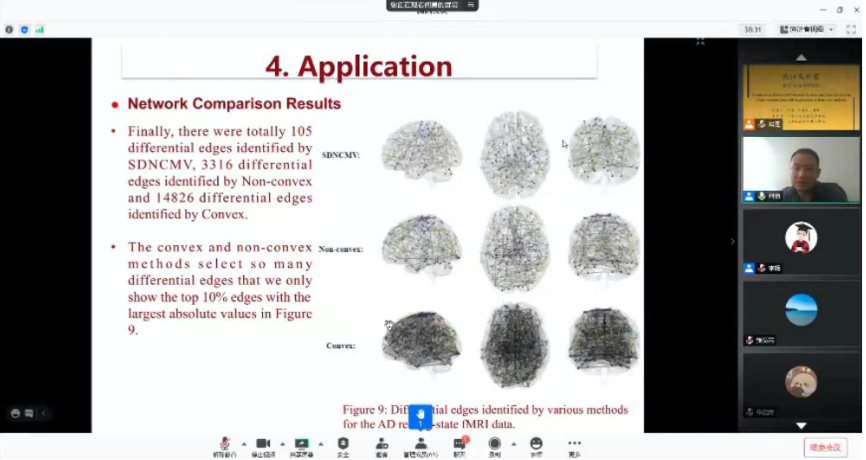
何勇指出,SDNCMV方法能够很好地应用于2003年的ADNI研究中收集的关于阿尔兹海默病大脑rs-fMRI的数据,进行一定的预处理后,61个研究对象被纳入研究分析,其中包括31个阿尔茨海默病患者和30个健康人,最终SDNCMV方法得出105个差异边并排序。最后何勇从新颖性、概括性、准确性和稳健性等四个角度对SDNCMV方法进行总结。
在交流讨论环节,在线师生积极提问。何勇对原始的每个个体得到的矩阵数据构造如何以及同一个体不同脑区在不同时刻的观测值等问题进行了进一步解答。
本次讲座介绍了一种应用于脑科学的差异网络分析方法,详尽地阐释了矩阵型数据的处理过程和实际应用。此后“统计大讲堂”系列将继续推出更多精彩讲座,敬请关注。