

3月9日上午,“统计大讲堂”系列讲座第185讲举行。本次讲座采取在线会议的方式,邀请阿尔伯塔大学数学与统计科学系副教授Linglong Kong作题为“Statistics and Optimization in Reinforcement Learning”的报告,讲座由中国人民大学统计学院教授许王莉主持。

许王莉首先介绍了主讲人的相关信息。Linglong Kong是阿尔伯塔大学数学与统计科学系副教授,加拿大统计学会主席。先后发表学术论文60余篇,包括AOS、JASA、JRSSB等顶级期刊。
Linglong Kong首先介绍了强化学习的基础概念,接着介绍了强化学习的四个主要类别以及数个应用领域,包括游戏,机器人,推荐系统,自动驾驶等。他指出,除期望之外,目标函数的分布情况同样具有重要研究价值。因此,他提出了DRL模型用于研究目标函数分布,该模型重新定义了奖励函数,可用于模拟系统随机性以及策略随机性。贝尔曼方程也随之发生如下改变。

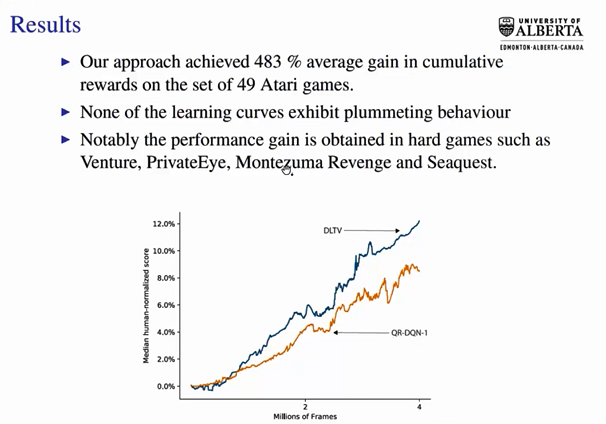
以该模型求解获得的分布可以运用于强化学习“探索-运用”困境中,此处Linglong Kong创立了DLTV探索方法,通过构建衰减左截断方差的方式寻求最优解。该方法在绝大多数情况下包括在自动驾驶领域数据下都取得了相较于传统方法更快、更优的结果。
而强化学习领域还存在着一个问题:由于算法和数据集的复杂性,该领域研究成果复现的时间成本较高,难以体现结果的可重复性。因此,加速求解过程具有重要意义。Linglong Kong从贝尔曼方程求固定点的角度出发,研究了安德森加速算法在强化学习领域的加速机制,收敛性和稳定性。
加速机制方面,Linglong Kong建立了安德森加速算法与准牛顿策略迭代法之间的关系。从而对于安德森加速算法有了更深入的认识;收敛性方面,Linglong Kong证明了安德森混合通过增加一个额外的收缩因子的方式增加了策略迭代方案的收敛半径;稳定性方面,Linglong Kong则提出了稳定的正则化,并将理论原则的MellowMax算子引入到安德森混合中,从而获得了稳定的安德森加速算法,并取得了较好的实验效果。

最后,在提问交流环节,在线师生积极参与讨论,Linglong Kong耐心解答了同学们的疑问,就强化学习领域问题做了更加深入的探讨。
此后“统计大讲堂”系列将陆续推出更多精彩讲座,敬请关注。